便利なコマンドをインストール
tree コマンドをインストールする
treeコマンドはディレクトリやファイルをツリー状に表示します。
$ sudo apt-get install tree
で、Ubuntu にインストールできます。
マニュアル
| オプション | 説明 |
| -a | 「.」で始まる隠しファイルも表示する |
| -d | ディレクトリのみツリー表示する |
| -l | シンボリックの場合、階層をたどる |
| -f | 実行したディレクトリからのパスを表示する |
| -Q | ファイルの名所を二重引用符で囲む |
| -p | 各ファイルのパーミッション情報を表示する |
| -g | ファイルのグループ名やグループID(GID)を表示する |
| -s | ファイルのサイズをバイト単位で表示する |
| -h | ファイルのサイズを単位で表示する |
| -v | バージョンごとにソートして表示する |
| -r | アルファベット順にソートして表示する |
| -t | 最後の変更時刻でソートして表示する |
| -c | 最後のステータス変更でソートして表示する |
| -U | ソートしないでディレクトリ順に表示する |
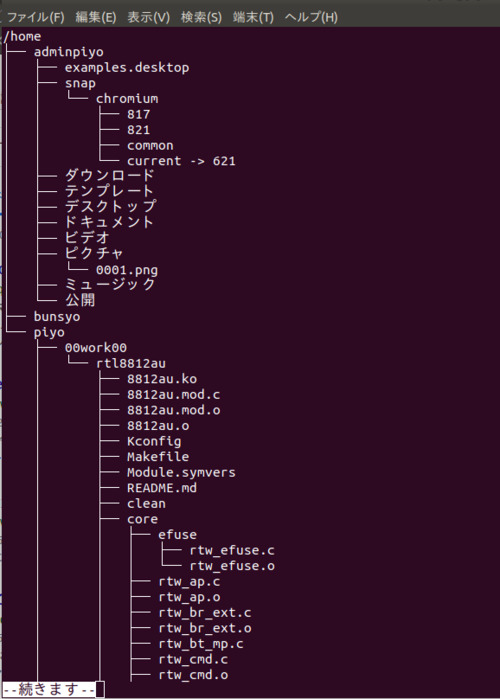
実行イメージ
ツリー状に表示する機能の他、ファイル名で絞り込み検索をしたり、パス付きでファイルの一覧表示をしたり、HTML形式で出力できます。
$ man tree と入力すると使い方が表示されます(英語)。
→ 【 tree 】コマンド――ディレクトリをツリー状に表示する の説明がわかりやすいです。
nkf コマンドをインストールする
nkf は文字コードと改行コードを変換するコマンドです。
$ sudo apt install nkf でインストールします。
| オプション名 | 説明 |
| -j | JISコードで出力します。 |
| -e | EUCコードで出力します。 |
| -s | Shift_JISコードで出力します。 |
| -w,-w80 | UTF8コード(BOMを記述しません。UTF8の場合、BOMはファイルがUTFで記述されていることを明確にするために使用されます。)で出力します |
| -w8 | UTF8コード(BOMを記述します。)で出力します |
| -w16,-w16B0 | ビッグエンディアンのUFT16コード(BOMを記述しません。UTF16の場合、BOMはファイルがビッグエンディアンであるかリトルエンディアンであるかを識別するために使用されます。)で出力します。 |
| -w16B | ビッグエンディアンのUFT16コード(BOMを記述します。)で出力します。 |
| -w16L | リトルエンディアンのUFT16コード(BOMを記述しません。)で出力します。 |
| -w16L0 | リトルエンディアンのUFT16コード(BOMを記述します。)で出力します。 |
| -mB | MIME(規格上ASCIIコードしか使えない電子メールで他の文字コードのテキストファイルやバイナリファイルを扱うための仕組みです。) Base64(データを印字可能な64種類の英数文字へ変換する方式です。)のデータを解読します。 |
| -mQ | MIME quoted(ASCIIコードに存在しない文字のみ「=??」といった形に変換します。「??」には16進数2桁の値が入ります。)のデータを解読します。 |
| -mS | 解読の際、MIMEを厳しくチェックします。 |
| -mN | 解読の際、MIMEのチェックを簡略化します。 |
| -m0 | MIMEの解読を行いません。 |
| -M | ヘッダ形式のMIMEに変換します。 |
| -MB | MIME Base64に変換します。 |
| -MQ | MIME quotedに変換します。 |
| -J | 入力したデータをISO-2022-JPと仮定して処理を行います。 |
| -E | 入力したデータをEUC-JPと仮定して処理を行います。 |
| -S | 入力したデータをShiftJisと仮定して処理を行います。 |
| -W | 入力したデータをUTF-8と仮定して処理を行います。 |
| -W8 | 入力したデータをUTF-8と仮定して処理を行います。 |
| -W16 | 入力したデータをリトルエンディアンのUTF-16と仮定して処理を行います。 |
| -W16B | 入力したデータをビッグエンディアンのUTF-16と仮定して処理を行います。 |
| -W16L | 入力したデータをリトルエンディアンのUTF-16と仮定して処理を行います。 |
| -x | 半角カナを全角カナに変換しません。 |
| -X | 半角カナを全角カナに変換します。 |
| -B | 入力したデータを破損したJISコードのデータと仮定して処理を行います。破損によりESCコードが消失したものとして処理します。 |
| -B1 | 「ESC+(」「ESC+$」の後の文字コードを無視します。 |
| -B2 | 改行の後は強制的にASCIIコードに戻します。 |
| -f[文字数[-マージン]] | 一行あたりの文字数を指定した文字数にし、指定されただけマージンを取ります。 |
| -Z -Z0 | JISX0208コードのアルファベットをASCIIコードに変換します。 |
| -Z1 | JISX0208コードの全角スペースをASCIIコードのスペース1文字分に変換します。 |
| -Z2 | JISX0208コードの全角スペースをASCIIコードのスペース2文字分に変換します。 |
| -Z3 | 「>」「<」「」「&」を「<」「>」「”」「&」に変換します。 |
| -b | 出力時にバッファリングを行います。 |
| -u | 出力時にバッファリングを行いません。 |
| -t | 何もしません。 |
| -I | ISO-2022-JP以外の文字コードの感じが存在した場合「==」に変換します。 |
| -i[ESCコード(@又はB)] | JIS漢字を示すESCコードを指定します。 |
| -o[ESCコード(B、J、Hのどれか)] | 1バイト英数文字を示すESCコードを指定します。 |
| -r | ROT13/47の変換を行います。 |
| -g | 識別した文字コードを表示します。 |
| -v | バージョン情報を表示します。 |
| -T | テキストモードで出力を行います。(MS-DOSでのみ有効です。) |
| -l | 「0x80」~「0xfe」を ISO-8859-1 (Latin-1)コードの文字として扱います。 |
| -O | ファイルに処理結果を出力します。 |
| -Lu,-d | 改行コードを「LF」(UNIXの改行コード)で出力します。 |
| -Lw,-c | 改行コードを「CR/LF」(Windowsの改行コード)で出力します。 |
| -Lm | 改行コードを「CR」(macの改行コード)で出力します。 |
| –fj, –unix, –mac, –msdos, –windows | 指定したシステムに合致した文字コードに変換します。 |
| –jis, –euc, –sjis, –mime, –base64 | 指定した文字コードで出力します。 |
| –hirakana, –katakana | ひらがな、カタカナに変換します。 |
| –fb-{skip, html, xml, perl, java, subchar | 変換できなかった文字の扱い方を指定します。 |
| –prefix=escape ESCコード 文字1 [文字2 ・・・] | 指定した文字の前に指定したESCコードを挿入します。 |
| –no-cp932ext | CP932の拡張文字を使用しません。 |
| –no-best-fit-chars | Unicodeからの変換の際、Unicodeへ変換しなおすことが出来ないものは変換しません。 |
| –cap-input, –url-input | %に続く16進数の値を文字に変換します。 |
| –numchar-input | Unicode文字参照を変換します。 |
| –in-place[=文字列], –overwrite[=文字列] | 元データを収めたファイルを出力結果で上書きします。 |
| –guess | 識別した文字コードを表示します。 |
| –help | 使用方法を表示します。 |
| –version | バージョン情報を表示します。 |
| — | オプションの記述の終了を宣言します。これ以降に-で始まる文字列があっても、オプションとして解釈されません。このオプションを使用することにより「-SampleText01.txt」等の「-」で始まるファイルを指定することが出来ます。 |
| –exec-in コマンド名 | 指定したコマンドを実行し、その出力をnkfで処理します。 |
| –exec-out コマンド名 | nkfで処理した結果を指定したコマンドに渡して実行します。 |
| –ic=入力文字コード,–oc=出力文字コード | 入・出力に使用する文字コードを指定します。指定可能な文字コードを以下に示します。 ISO-2022-JP,ISO-2022-JP-1,ISO-2022-JP-3,EUC-JP,EUC-JISX0213,EUC-JIS-2004,eucJP-ascii,eucJP-ms,CP51932,Shift_JIS,Shift_JISX0213,Shift_JIS-2004,CP932,UTF-8 UTF-8N,UTF-8-BOM,UTF8-MAC,UTF-16 UTF-16BE-BOM,UTF-16BE,UTF |
日本語文字コードについて
パソコン上に日本語表示をさせるために、日本語文字コードがあります。
「EUC-JP」「Shift_JIS」「UTF-8」の3つの日本語文字コードが普及しています。他に「SO-2022-JP(電子メール)」や「UTF-16」など様々な文字コードがあります。
2006年頃は、Webサイトで使う日本語は Shif_JIS が多く使われていましたが、現在は UTF-8 が広く使われています。
マイクロソフト社が パソコン用に「Shift_JIS」を使った日本語表示をJIS規格に登録したのが1982年です。
一方、UNIX は「EUC-JP」という文字コード規格を使うようになりました。
インターネットが普及し、誰もがパソコンを使う環境になってきた時に、「Unicode」という新しい文字コードが誕生し Ubuntu では、Unicode の一種の UTF-8 を使うようになりました。
複数の日本語文字コードが存在した時期があり、Perl言語などは EUC-JP で書かれたプログラムも多く存在しています。
このように日本語文字コードが混在しているため nkf コマンドを使って日本語コードの変換処理 を行います。
あなたの日本語環境は?
$ set | grep -i lang
と端末エミュレータに入力してください。
僕の場合は
LANG=ja_JP.UTF-8
LANGUAGE=ja:en
と表示されました。
これは、環境変数のひとつLANG環境変数が表示された状態です。
LANG=ja_JP.UTF-8 と表示されているので、僕の日本語環境は UTF-8 を使う設定になっている事がわかります。
次回は「環境変数」についての説明をしたいと思っています。